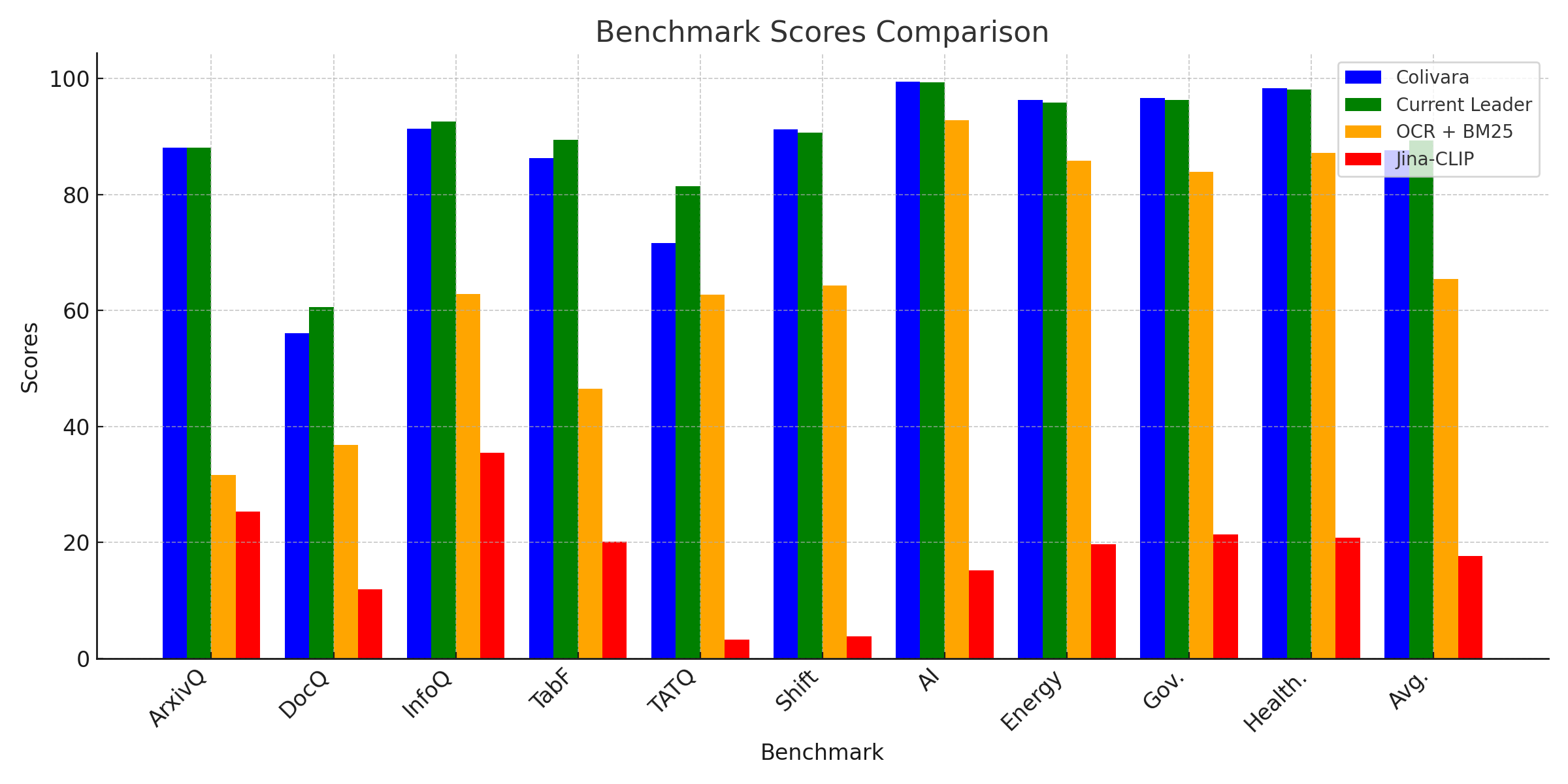
About ColiVara
Colivara is a state of the art retrieval API that allows you to store, search, and retrieve documents based on their visual embeddings.
Documents are visually rich structures that convey information through text, as well as tables, figures, page layouts, and charts. While legacy document retrieval systems exhibit good performance on query-to-text matching, they struggle to pass visual cues efficiently to large language models, hindering their performance on practical document retrieval applications such as Retrieval Augmented Generation.
It is a web-first implementation of the ColPali paper using ColQwen2 as the LLM model. It works exactly like RAG from the end-user standpoint - but using vision models instead of chunking and text-processing for documents.